
generated by nano 🍌
In the previous article, Different Chunking Methods for RAG, we explored several strategies used to split documents before feeding them into a Retrieval-Augmented Generation (RAG) pipeline.
In this chapter, we’ll go deeper into Semantic Chunking — one of the most powerful techniques for improving retrieval accuracy in modern RAG systems.
We’ll cover:
- What semantic chunking actually means ?
- How it works internally ?
- Why it improves retrieval accuracy ?
- How it compares to other chunking strategies used in production systems ?
Why Traditional Chunking Often Fails
Most early RAG pipelines relied on fixed-size chunking, where documents are split into chunks of predefined size (for example, 500 tokens with a 50 token overlap).
While this approach is simple, it introduces a fundamental problem:
it ignores the semantic structure of the text.
For example, imagine a paragraph discussing transformer architectures, followed by another paragraph explaining reinforcement learning. A fixed-size splitter might cut the text in the middle of the explanation, creating chunks that contain partial or mixed topics.
This leads to two common issues:
- Context fragmentation – important ideas get split across chunks.
- Noisy retrieval – chunks contain unrelated information.
When these chunks are retrieved during query time, the LLM receives incomplete or irrelevant context, which directly reduces answer quality.
What is Semantic Chunking?
Semantic chunking is a strategy that splits documents based on meaning rather than size.
Instead of arbitrarily cutting text every few hundred tokens, semantic chunking groups sentences that discuss the same topic.
The goal is simple:
Each chunk should represent a coherent semantic idea.
For example, consider the following sequence of sentences:
Sentence 1: Explanation of transformers Sentence 2: Attention mechanism in transformers Sentence 3: Multi-head attention architecture Sentence 4: Reinforcement learning algorithms
A semantic chunker would produce:
Chunk 1 → Sentences 1–3 (transformer topic) Chunk 2 → Sentence 4 (new topic)
This ensures that each chunk represents a complete concept, which significantly improves retrieval relevance.
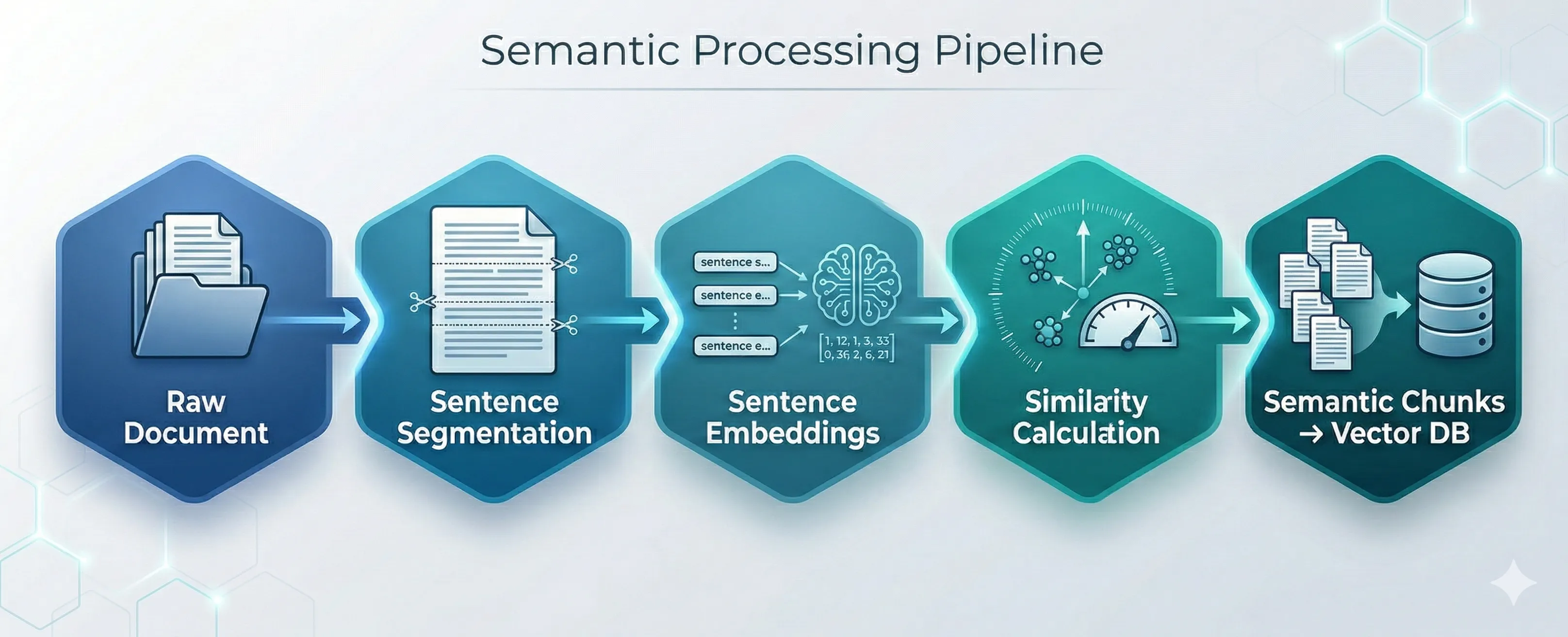
How Semantic Chunking Works
Most semantic chunking implementations follow a similar pipeline.
Step 1 — Sentence Segmentation
The document is first split into sentences.
Example:
Document → Sentence1, Sentence2, Sentence3, Sentence4This allows the algorithm to analyze semantic similarity at a granular level.
Step 2 — Generate Sentence Embeddings
Each sentence is converted into a vector representation using an embedding model.
Common embedding models include:
- Sentence Transformers
- BGE embeddings
- Instructor embeddings
- OpenAI embeddings
Each sentence is now represented as a high-dimensional vector capturing its meaning.
Step 3 — Compute Similarity Between Sentences
Next, the algorithm calculates cosine similarity between consecutive sentences.
Example:
similarity(S1, S2)
similarity(S2, S3)
similarity(S3, S4)High similarity indicates the sentences belong to the same topic, while low similarity suggests a topic shift.
Step 4 — Detect Topic Boundaries
If the similarity between sentences drops below a predefined threshold, a new chunk boundary is created.
Example rule:
similarity > 0.75 → same chunk
similarity < 0.65 → start new chunkThis dynamically segments the document based on semantic transitions.
Step 5 — Build Semantic Chunks
Finally, sentences are grouped into chunks that maintain topic continuity.
Unlike fixed chunking, semantic chunks may vary in size, but they maintain contextual coherence.
generated by nano 🍌
Why Semantic Chunking Improves RAG Performance
Semantic chunking improves RAG pipelines in several important ways.
1. Better Context Integrity
Each chunk contains a complete explanation of a concept, which helps the LLM reason more effectively.
2. Higher Retrieval Precision
Vector similarity search works best when chunks represent clear semantic topics rather than mixed content.
3. Reduced Hallucination
When retrieved context is precise and coherent, the LLM is less likely to generate unsupported information.
4. Improved Answer Grounding
Because chunks are semantically aligned, answers are better supported by retrieved documents.
Accuracy Comparison with Other Chunking Methods
Across many internal and industry experiments, semantic chunking tends to outperform traditional chunking approaches.
| Chunking Method | Retrieval Precision | Context Quality | Implementation Effort |
|---|---|---|---|
| Fixed Token Chunking | Medium | Low | Easy |
| Recursive Chunking | Medium–High | Medium | Moderate |
| Semantic Chunking | High | High | Advanced |
In many RAG systems, teams report:
- 15–30% improvement in retrieval relevance
- More grounded responses
- Lower hallucination rates
These improvements become especially noticeable in long-form documents like research papers, legal documents, or technical documentation.
Practical Challenges
Despite its advantages, semantic chunking is not always trivial to implement.
Some practical challenges include:
Higher compute cost Generating embeddings for every sentence can be expensive for large document sets.
Threshold tuning The similarity threshold must be tuned carefully to avoid overly small or overly large chunks.
Variable chunk sizes Chunks can become uneven, which sometimes requires adding a maximum token limit.
Production Best Practices
In most production RAG systems, semantic chunking is combined with token limits and overlap strategies.
A common configuration looks like this:
Semantic similarity threshold: 0.75
Max chunk size: 800 tokens
Overlap: 50 tokensThis ensures chunks remain semantically meaningful while staying within model limits.
What’s Next
Semantic chunking is a powerful technique, but it’s just one piece of the puzzle. In the next chapter, we’ll explore Agentic Chunking — a dynamic approach where the LLM itself decides how to group information based on meaning and relevance, evolving chunk metadata over time.
Follow along as we discuss Agentic Chunking in our next chapter.