TL;DR: Bad chunks = bad retrieval = hallucinations. Agentic chunking fixes this by making an LLM reason about meaning — not just mechanics.

generated by nano 🍌
The Real Reason RAG Fails
You embedded your docs. You picked a great model. Answers are still shallow and wrong.
The culprit isn’t your model. It’s your chunks.
Split ideas in the wrong place and your retriever returns broken context. Your model hallucinates to fill the gaps. Traditional chunking optimizes for speed — agentic chunking optimizes for understanding.
The Chunking Showdown
| Method | How It Works | Strengths | Weaknesses |
|---|---|---|---|
| Fixed-Size | Split every N tokens | Fast, cheap | Cuts mid-idea, mixes unrelated concepts |
| Semantic | Split at similarity boundaries | More natural breaks | Still static, misses long-range links |
| Proposition-Based | Extract atomic facts first | High granularity, factually precise | Can feel fragmented without smart grouping |
| Agentic | LLM decides chunk membership + evolves metadata | Meaning-first, dynamic, coherent | More LLM calls, higher indexing cost |
What Makes Agentic Chunking Different
It behaves like a good editor, not a pair of scissors:
- Generalizes across vocabulary — apples, pizza, and sushi all become
food_preferences - Evolves chunk metadata dynamically — titles and summaries refresh as new content is added, improving retrieval ranking
- Handles real-world mess — blogs, research notes, and docs that repeat or shift topics don’t break it
The Core Loop
Built on the Dense X Retrieval paper (arXiv:2312.06648) which proved propositions outperform sentences and passages as retrieval units:
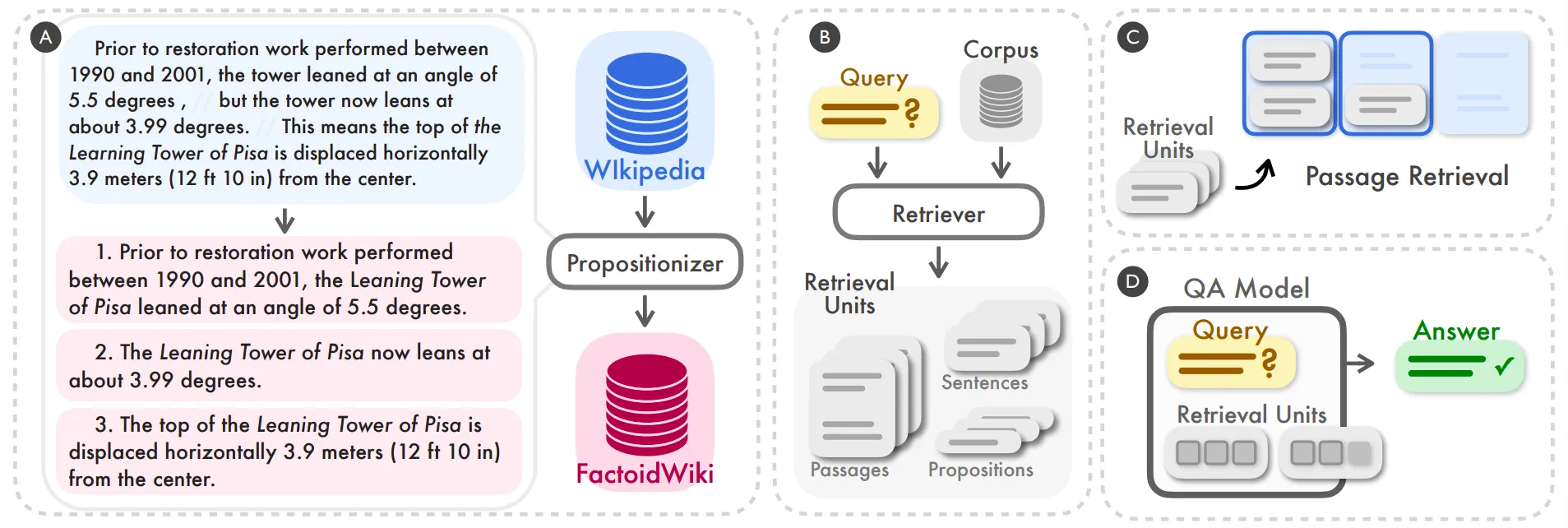
generated by nano 🍌
for proposition in extract_propositions(document):
chunk_id = find_relevant_chunk(proposition, chunk_outline)
if chunk_id:
add_to_chunk(chunk_id, proposition)
refresh_metadata(chunk_id)
else:
create_new_chunk(proposition)For reliable structured output from the LLM:
class ChunkID(BaseModel):
chunk_id: str | None = NoneWant to try this in LangChain? The community prompt is live here: 🔗 kumja/proposal-indexing on LangSmith Hub
🌽 The Corn Test
Your knowledge base contains three corn-related facts: fresh corn, corn tortillas, and high-fructose corn syrup.
A fixed-size chunker mashes them together. A query about healthy snacks retrieves the corn syrup fact too — poisoning your context.
An agentic chunker separates them into fresh_produce, traditional_cuisine, and food_additives. The right chunk, the right query, the right answer.
If your chunking can handle corn, it can handle production data.
Honest Tradeoff
Need ultra-low cost and latency? Semantic chunking is fine.
Need retrieval quality you can trust? Agentic chunking is worth the extra LLM calls — especially for long-form docs, overlapping topics, or any pipeline where a wrong answer has real consequences.
FAQs
Is agentic chunking the same as proposition-based chunking? No — propositions are the raw material. Agentic chunking is the assembly process that groups them intelligently.
Does it work with any embedding model? Yes. It’s a pre-processing step. Embed with whatever you prefer after chunking.
Best model to use as the agent? Smaller models (Haiku, GPT-4o-mini) handle chunk assignment well. Use larger models for generating high-quality titles and summaries.
Good for real-time ingestion? Best for batch indexing. For real-time, run semantic chunking fast and agentic chunking async in the background.
📄 Research: Chen et al. (2023). Dense X Retrieval. arXiv:2312.06648 🔗 LangSmith Prompt: kumja/proposal-indexing